[Python] Python 특수 메서드
Python의 특수 메서드에 대해 살펴봅니다.
개요
안녕하세요.
이번 글에서는 Python의 특수 메서드에 대해 살펴보겠습니다.
특수 메서드 개요
개념
파이썬 공식 문서에서는 다음과 같이 설명하고 있습니다.
파이썬의 클래스는 특수 구문에 의해 호출되는 특정 연산을 구현할 수 있습니다.
이것은 연산자 오버로딩에 대한 Python의 접근 방식으로, 클래스가 언어 연산자와 관련하여 자신의 동작을 정의할 수 있습니다.
쉽게 이야기하자면, 직접 작성한 클래스에서도 각종 연산자나 이터레이터가 동작할 수 있다는 걸 의미합니다.
특징
1. 사용자 정의 가능
특수 메서드는 파이썬 기본 연산의 행동을 직접 정의할 수 있도록 돕습니다.
예를 들어 __add__는 + 기호의 행동을 정의합니다.
2. 가독성
일반적인 연산을 통해 더 읽기 쉬운 문법을 지원합니다.
예를 들어 class_a.add_to(class_b) 보다는 class_a + class_b 가 보다 읽기 쉽습니다.
3. 통합성
파이썬의 내장형 함수과 모듈과 원활하게 통합 가능합니다.
예를 들어 __str__를 정의한다면, str() 함수를 사용할 수 있습니다.
간단한 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Point():
def __init__(self, x=0, y=0):
self.__x = x
self.__y = y
def __str__(self):
return f"({self.__x}, {self.__y})"
def __add__(self, other):
return Point(self.__x + other.__x, self.__y + other.__y)
if __name__ == "__main__":
mp1 = Point(1, 2)
mp2 = Point(2, 4)
print(mp1 + mp2) # output: (3, 6)
위의 코드는 2가지 특수 메서드인 __init__, __add__를 정의한 Point 클래스의 예시입니다.
__init__는 객체를 생성할 때 호출되는 메서드입니다.
Point 클래스는 생성할 때 x와 y 값을 전달하여 설정할 수 있습니다.
__add__는 객체 사이에 + 연산을 수행할 때 호출되는 메서드입니다.
따라서 Point 객체는 + 연산을 지원하며 그 결과로 두 객체의 x값과 y값을 합친 새로운 객체를 반환합니다.
종류
특수 메서드는 다양한 종류가 존재합니다.
다음은 개인적으로 많이 사용했던 특수 메서드를 정리한 표입니다.
자세한 내용은 다음 공식 문서 링크(바로가기)를 참고하세요!
| 함수명 | 설명 | 예시 |
|---|---|---|
__init__(self[, ...]) | 객체가 생성된 이후 호출자에게 돌려주기 전에 호출합니다. | class_a = MyClass() <-> class_a = MyClass__init__() |
__del__(self) | 객체가 파괴되기 직전에 호출합니다. | del class_a <-> class_a.__del__() |
__str__(self) | str(object) 또는 format(), print()에 의해 호출되어 비형식적인 문자열 표현을 계산합니다. | print(class_a) <-> print(class_a.__str__()) |
__getitem__(self, key) | self[key]의 실행 결과를 | my_custom_class[key] <-> my_custom_class.__getitem__(key) |
__len__(self) | 객체의 길이를 돌려줍니다. | len(class_a) <-> class_a.__len__() |
특수 메서드 활용
생성자 정의
1
2
3
4
5
class Customer():
def __init__(self, name, age, hobby):
self.__name = name
self.__age = age
self.__hobby = hobby
__init__를 이용해 객체가 생성될 때 인자를 넘겨서 초기화합니다.
반대로 객체가 파괴될 때 수행할 동작이 있다면 __del__을 정의하면 되겠죠??
연산자 오버로딩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
class Customer():
def __init__(self, name, age, hobby):
self.__name = name
self.__age = age
self.__hobby = hobby
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
self.__name = name
@property
def age(self):
return self.__age
@age.setter
def age(self, age):
self.__age = age
@property
def hobby(self):
return self.__hobby
@hobby.setter
def hobby(self, hobby):
self.__hobby = hobby
class CustomerGroup():
def __init__(self, name, customers = list()):
self.__name = name
if all(type(customer) == Customer for customer in customers):
self.__customers = customers
else:
self.__customers = list()
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
self.__name = name
@property
def customers(self):
return self.__customers
@customers.setter
def customers(self, customers):
self.__customers = customers
def __add__(self, other):
if isinstance(other, Customer):
return CustomerGroup(self.name, self.customers + [other])
elif isinstance(other, CustomerGroup):
return CustomerGroup(self.name + "-" + other.name, self.customers + other.customers)
if __name__ == "__main__":
cg_10 = CustomerGroup("cg_10")
cg_10 += Customer("Kim", 11, "swimming")
cg_20_40 = CustomerGroup("cg_20_40")
cg_20_40 += Customer("V", 23, "writing")
cg_20_40 += Customer("J", 38, "wacthing movie")
cg_20_40 += Customer("B", 44, "playing chess")
cg_10_40 = cg_10 + cg_20_40
print([(customer.name, customer.hobby) for customer in cg_10.customers])
print([(customer.name, customer.hobby) for customer in cg_20_40.customers])
print([(customer.name, customer.hobby) for customer in cg_10_40.customers])
고객 그룹을 저장하는 CustomerGroup 클래스의 예시입니다.
CustomerGroup 객체의 내용을 더할 때 __add__ 메서드를 활용하여 보다 직관적으로 사용할 수 있습니다.
여기서는 Customer 객체 1개를 더하거나 같은 CustomerGroup 객체를 더하는 용도로 사용했습니다.
내장형 데이터 모델 모방
마지막으로 특수 메서드의 조합을 통해 내장형 데이터 모델의 모방이 가능합니다.
이에 앞서 어떤 데이터 모델이 존재하는지 간략하게 살펴보겠습니다.
데이터 모델
파이썬의 내장형 데이터 모델은 크게 다음의 이미지를 따라갑니다.
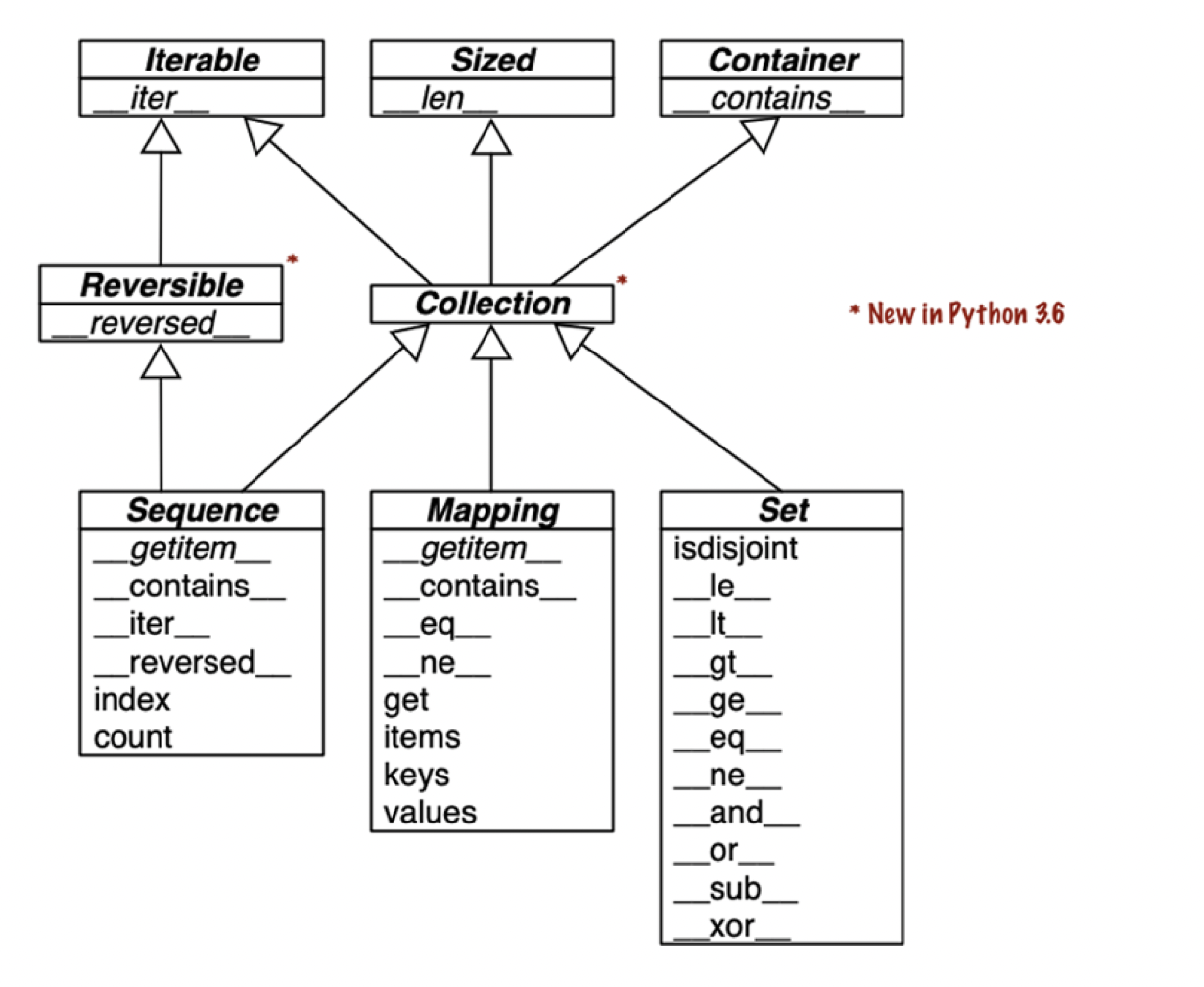 [그림01] 데이터 모델
[그림01] 데이터 모델
Sequence의 대표적인 예시는 List와 Tuple입니다.
순차적으로 저장된 것이 특징으로 인덱싱과 슬라이싱이 가능합니다.
Mapping의 대표적인 예시는 Dict입니다.
키와 값의 쌍으로 저장된 것이 특징입니다.
Set의 대표적인 예시는 Set입니다.
중복되지 않는 값들이 저장된 것이 특징으로 다양한 집합 연산을 지원합니다.
3개의 데이터 모델은 공통적으로 iterable하다는 특징을 가집니다.
이 글에서는 Sequence를 모방하기 위해 __getitem__와 __len__를 정의해보겠습니다.
해당 내용은 Docstring에서 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
...
class Sequence(Reversible, Collection):
"""All the operations on a read-only sequence.
Concrete subclasses must override __new__ or __init__,
__getitem__, and __len__.
"""
__slots__ = ()
...
예시: Sequence와 유사한 커스텀 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
class Point():
def __init__(self, x=0, y=0):
self.__x = x
self.__y = y
def __str__(self):
return f"({self.__x}, {self.__y})"
def __add__(self, other):
return Point(self.__x + other.__x, self.__y + other.__y)
def __truediv__(self, other):
if isinstance(other, (int, float)):
return Point(self.__x / other, self.__y / other)
class Skeleton():
def __init__(self, points=None):
if points:
self.__points = [
Point(x, y)
for x, y in points
]
else:
self.__points = [
Point(0, 0)
for _ in range(10)
]
def __getitem__(self, key):
return self.__points[key]
def __len__(self):
return len(self.__points)
if __name__ == "__main__":
import random
from functools import reduce
random.seed("2023-01-01")
my_skeleton = Skeleton([(random.randint(1, 255), random.randint(1, 255)) for _ in range(10)])
print("==========")
print("first point:", my_skeleton[0])
print("==========")
for i, each_point in enumerate(my_skeleton):
print(f"({i+1}/10) point:", each_point)
print("==========")
for each_point in my_skeleton[1::3]:
print(f"each point:", each_point)
print("==========")
print(f"{my_skeleton[0]} in skeleton?? ->", my_skeleton[0] in my_skeleton)
print("==========")
print("point average:", reduce(lambda acc, cur: acc + cur, my_skeleton) / 10)
__getitem__와 __len__를 정의해 파이썬의 Sequence를 모방한 Skeleton 클래스의 예시입니다.
Skeleton 클래스는 인덱싱, 슬라이싱, 멤버 검사(in), 반복 등 Sequence 클래스와 유사하게 동작합니다!
마무리하며
이번 글에서는 파이썬의 특수 메서드를 살펴보았습니다.
생성자 및 소멸자, 연산자 오버로딩, 내장형 함수 및 모듈과의 호환성 등 특수 메서드가 지원하는 다양한 기능을 확인할 수 있었습니다.
또한 특수 메서드의 조합을 통해 내장형 데이터 모델을 모방할 수 있다는 점도 확인해보았습니다.
현재 글은 공부 중 작성한 것으로 부족한 점이 많습니다.
글을 읽으시면서 보완할 점이나 오류 등은 댓글로 부탁드리겠습니다~!
이 글이 조금이나마 도움이 되셨으면 합니다.
감사합니다. 😀
참고 문헌
- 특수 메서드 이름들, https://docs.python.org/ko/3/reference/datamodel.html#special-method-names
- collections.abc — 컨테이너의 추상 베이스 클래스, https://docs.python.org/ko/3/library/collections.abc.html
- _collections_abc.py, https://github.com/python/cpython/blob/main/Lib/_collections_abc.py#L989