[Python] Python GIL(Global Interpreter Lock) 살펴보기
Python의 GIL(Global Interpreter Lock)에 대해 살펴봅니다.
개요
안녕하세요.
이번 글에서는 파이썬의 GIL(Global Interpreter Lock)에 대해 살펴보겠습니다.
GIL 개요
GIL의 정의
GIL은 Global Interpreter Lock의 줄임말입니다.
단순하게 해석하면 “전역 인트프리터 락”이라는 뜻이죠.
파이썬 공식 위키에서는 GIL을 "멀티 스레드가 바이트 코드를 동시에 실행하지 못하도록 파이썬 오브젝트의 접근을 방지하는 뮤텍스" 라고 설명합니다.
다행히 I/O나 이미지 프로세싱, Numpy의 대용량 계산 같은 경우는 GIL에 해당되지 않습니다.
멀티 스레드 프로그램에서는 GIL이 bottleneck으로 동작할 수 있습니다.
또한 멀티 코어 하드웨어에서는 큰 시스템 콜 오버헤드가 지나치게 커질 가능성이 존재합니다.
게다가 CPU 바운드 thread보다 먼저 계획된 I/O 바운드 thread를 생성해서 signal의 전송을 막을 수 있습니다.
GIL에 앞선 선행지식
Mutex(뮤텍스, 상호 배제)
뮤텍스는 상호 배제(MUTual EXclusion)의 약자입니다.
풀어 말하면 임계구역을 같이 접근하지 못 하도록 프로세스나 스레드를 제한하는 개념입니다.
자세한 내용은 이전 포스트([CS] 프로세스와 스레드 04 - 프로세스와 상호배제)에서 확인 가능합니다.
임계구역
임계구역이란 서로 다른 2개 이상의 프로세스 혹은 스레드 등 처리 단위가 같이 접근해서는 안 되는 공유 영역를 의미합니다.
뮤텍스 구조
가장 단순한 구조의 뮤텍스는 다음 2가지 연산으로 구분됩니다.
- lock: 현재의 임계 구역에 들어갈 권한을 얻어온다. 만일 다른 프로세스/스레드가 임계 구역을 수행 중이라면 종료할때까지 대기한다(entry section)
- unlock: 현재의 임계 구역을 모두 사용했음을 알린다. 대기중인 다른 프로세스/스레드가 임계 구역에 진입할 수 있다(exit section).
POSIX Thread
POSIX Thread(pthread)는 POSIX 규격에 부합하는 프로그래밍 언어 독립적이고 병렬 실행 가능한 모델입니다.
자세한 사항은 이전 포스트([Develop] POSIX)를 참고해주세요!
파이썬 Thread
파이썬의 thread는 POSIX thread(Pthread)와 window thread입니다.
이는 운영체제에 의해 관리됩니다.
또한 C로 작성된 파이썬 인터프리터 프로세스의 스레드 실행을 나타냅니다.
동시성과 병렬성
동시성(Concurrency)과 병렬성(Parallelism)은 헷갈리기 쉬운 개념입니다.
동시성은 동시에 실행하는 것처럼 빠르게 작업을 전환하여 실행합니다.
반면 병렬성은 실제로 여러 작업을 처리합니다.
따라서 동시성에서 시스템 자원을 공유하는 동안 병렬성에서는 각자 자원을 할당받을 수 있습니다.
동시성은 시스템 자원을 효율적으로 사용하며 동시에 진행할 수 있도록 응답성을 제공합니다.
병렬성은 여러 작업을 동시에 실행해 속도와 성능을 향상시킵니다.
스래싱과 호위 효과
위키백과에서는 스래싱(thrashing)을 “컴퓨터의 가상 메모리 리소스가 과도하게 사용되면서 페이징 및 페이지 장애가 지속적으로 발생하고 대부분의 응용 프로그램 수준 처리를 방해하는 것”이라고 설명합니다.
프로세스나 스레드는 실행을 위해 일정 크기 이상의 가상 메모리 리소스가 필요합니다.
한편 프로세스나 스레드는 특정 신호를 받았을 때 작업을 멈추고 각자 실행에 필요한 내용을 대기 큐에 삽입합니다.
만약 프로세스나 스레드가 컴퓨터 처리 능력 이상으로 중단되고 재실행된다면 대기 큐에 저장된 내용이 많아집니다.
이 상황이 지속된다면 메모리의 페이징과 페이지 장애가 늘어나게 됩니다.
그러다 어느 순간이 되면 새로운 프로세스와 스레드를 위한 페이징을 시작할 수 없을 지경에 이릅니다.
위와 같은 상태가 바로 스래싱입니다.
한편, 호위 효과(Convey Effect)는 프로세스 스케줄링 알고리즘 중 FCFS(First-Come-First-Serve)에서 발생하는 현상입니다.
실행시간이 짧은 프로세스들(process_short1, process_short2)과 긴 프로세스(process_long)가 있다고 가정하겠습니다.
process_short1과 process_short2를 먼저 처리 후 process_long을 실행한다면 대기시간이 비교적 짧습니다.
하지만 반대로 process_long을 먼저 처리 후 process_short1과 process_short2를 실행한다면 대기시간이 길어지면서 효율이 떨어집니다.
이와 같은 상황이 바로 호위 효과입니다.
자세한 내용은 이전 포스트([CS] 프로세스와 스레드 05 - 프로세스와 여러 현상)를 참고해주세요.
GIL of Python < 3.2
3.2까지의 GIL 획득 방법은 “주기적인 tick의 확인”입니다.
이 확인은 100 ticks 마다 수행합니다.
동작 과정
- tick 카운터를 초기화합니다.
- 메인 thread가 있다면 signal 핸들러를 실행합니다.
- GIL을 해제합니다.
- GIL을 다시 얻습니다.
구조
파이썬 인터프리터는 다른 모든 thread의 동기화 기초작업을 생성하기 위해 사용하는 C기반의 싱글 lock만 제공합니다.
이는 단순한 mutex가 아니라 pthreads mutex와 상태 변수로 구성된 이진 semaphore입니다.
GIL은 이 lock의 인스턴스이며 실제 구성은 다음과 같습니다.
1
2
3
locked = 0 # Lock status
mutex = pthreads_mutex() # Lock for the status
cond = pthreads_cond() # Used for waiting/wakeup
다음은 GIL의 획득 및 해제의 의사코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
release() {
mutex.acquire()
locked = 0
mutex.release()
cond.signal()
}
acquire() {
mutex.acquire()
while (locked) {
cond.wait(mutex)
}
locked = 1
mutex.release()
}
예시1: thread1의 I/O 작업 수행
thread1과 thread2가 존재하며 thread1이 I/O 작업을 수행하는 경우입니다.
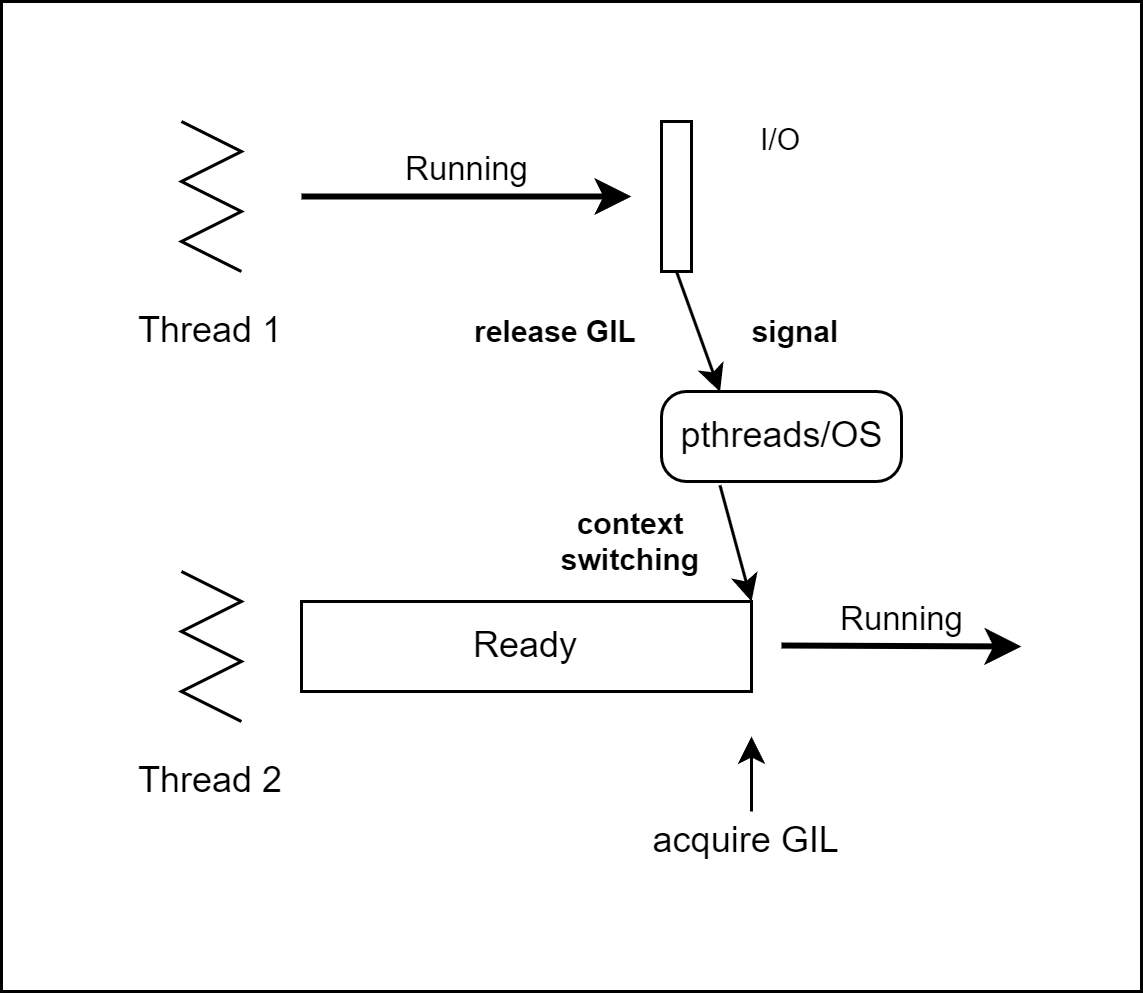 [그림01] 3.2 이전 버전의 간단한 thread
[그림01] 3.2 이전 버전의 간단한 thread
전체 과정은 운영체제와 thread 라이브러리가 처리합니다.
- thread1이 GIL을 얻은 채로 작업을 수행합니다. thread2는 GIL을 얻기 위해 대기합니다.
- thread1이 I/O 작업을 하면서 GIL을 해제하고 signal을 보냅니다.
- thread2는 문맥 교환을 하고 GIL을 획득합니다.
- thread2가 작업을 시작합니다.
예시2: thread1이 확인될 때까지 수행
thread1과 thread2가 존재하며 thread1의 확인까지(100 ticks까지) 작업하는 경우입니다.
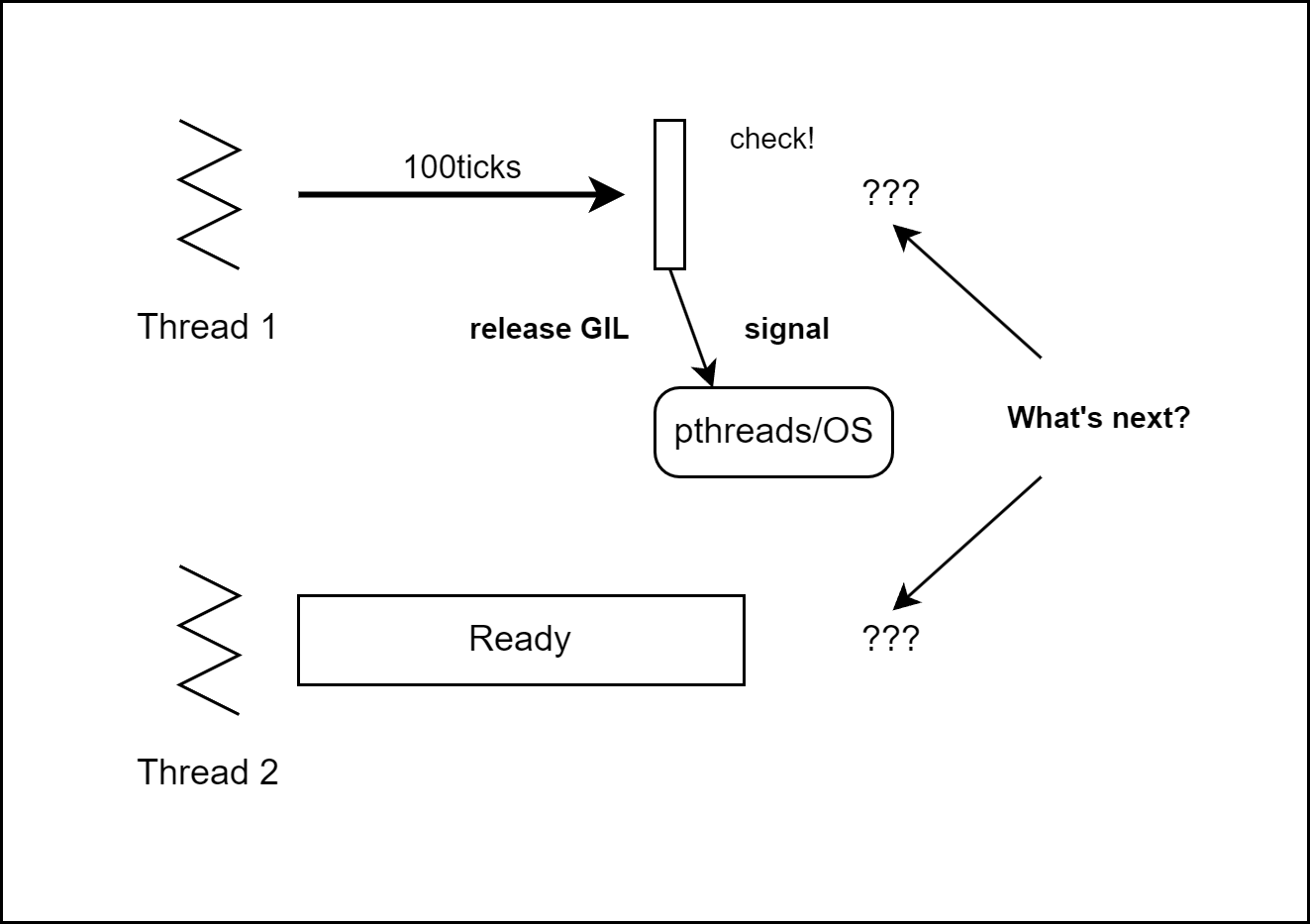 [그림02] 3.2 이전 버전의 복잡한 thread
[그림02] 3.2 이전 버전의 복잡한 thread
- thread1이 GIL을 얻은 채로 작업을 수행합니다. thread2는 GIL을 얻기 위해 대기합니다.
- thread1의 tick이 남아있지 않으므로 GIL을 해제하고 signal을 보냅니다.
- thread1과 thread2 중 어느 thread가 실행될까요…??
상태 변수는 우선순위를 가지는 내부 대기 큐를 포함합니다.
따라서 시그널을 보낸 thread1은 대기 큐에 삽입됩니다.
이후 대기 큐에서 우선순위가 높은 thread가 GIL을 획득하고 작업을 수행합니다.
따라서 다음과 같이 thread1이 작업을 이어갈 수도 있고 또는 thread2에서 새롭게 작업을 수행할 수도 있습니다.
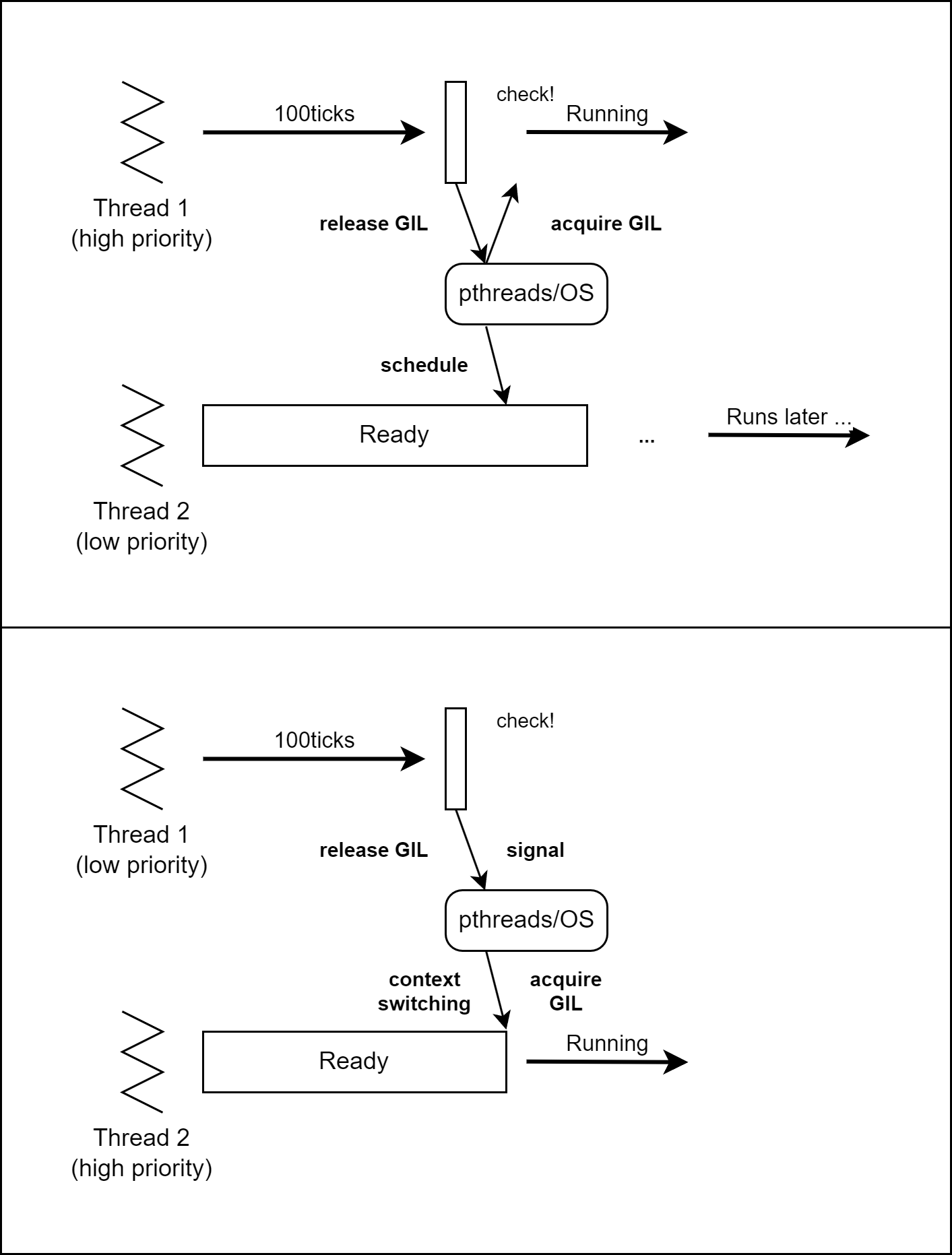 [그림03] 3.2 이전 버전의 thread switching
[그림03] 3.2 이전 버전의 thread switching
기존 GIL의 난점: GIL thrashing
이전 GIL은 싱글코어에서 thread 문맥 교환이 이뤄지기 전에 수백 ~ 수천 번의 확인을 할 수 있지만 이는 큰 부담이 되지 않습니다.
하지만 멀티코어에서는 thread가 동시에 실행되서 GIL을 두고 thread 사이에 경쟁이 일어날 수 있습니다.
다음 그림을 보면 신호를 받은 thread2는 지속적으로 문맥교환 뒤 작업을 시도하지만 GIL을 획득하지 못해 다시 대기 상태에 진입합니다.
만약 이 과정이 수백 ~ 수천 번 발생한다면 많은 부하가 발생합니다..!!
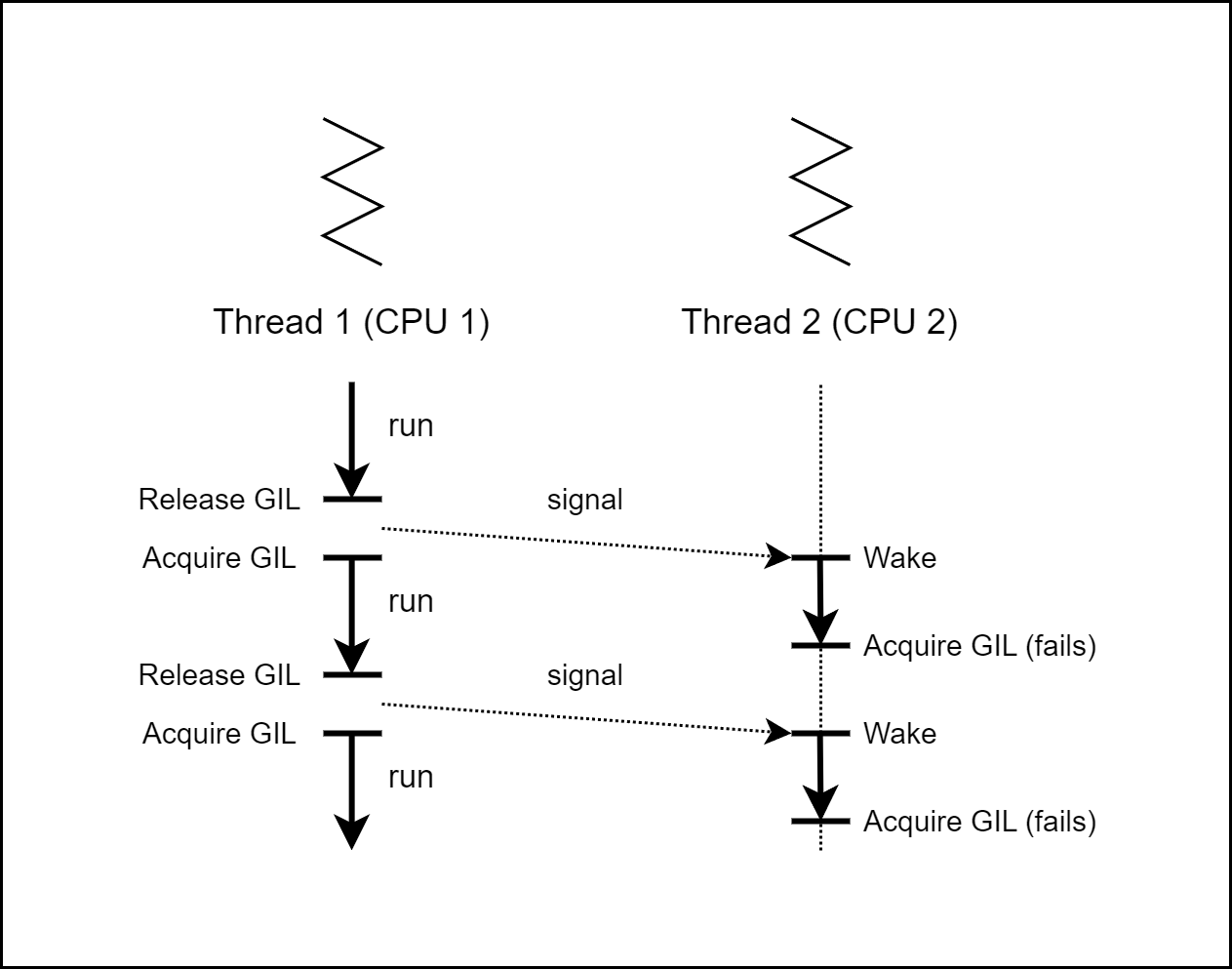 [그림04] 3.2 이전 버전의 thrashing
[그림04] 3.2 이전 버전의 thrashing
그렇다면 언제 이런 상황이 발생할까요??
I/O명령은 차단되지 않는 경우가 많습니다.
버퍼링 덕분에 OS는 I/O 요청을 바로 처리할 수 있으며 thread 작업을 이어서 수행합니다.
그렇지만 요청이 올 때마다 GIL은 항상 해제됩니다.
이 과정이 반복되면 결과적으로 GIL thrashing이 발생합니다.
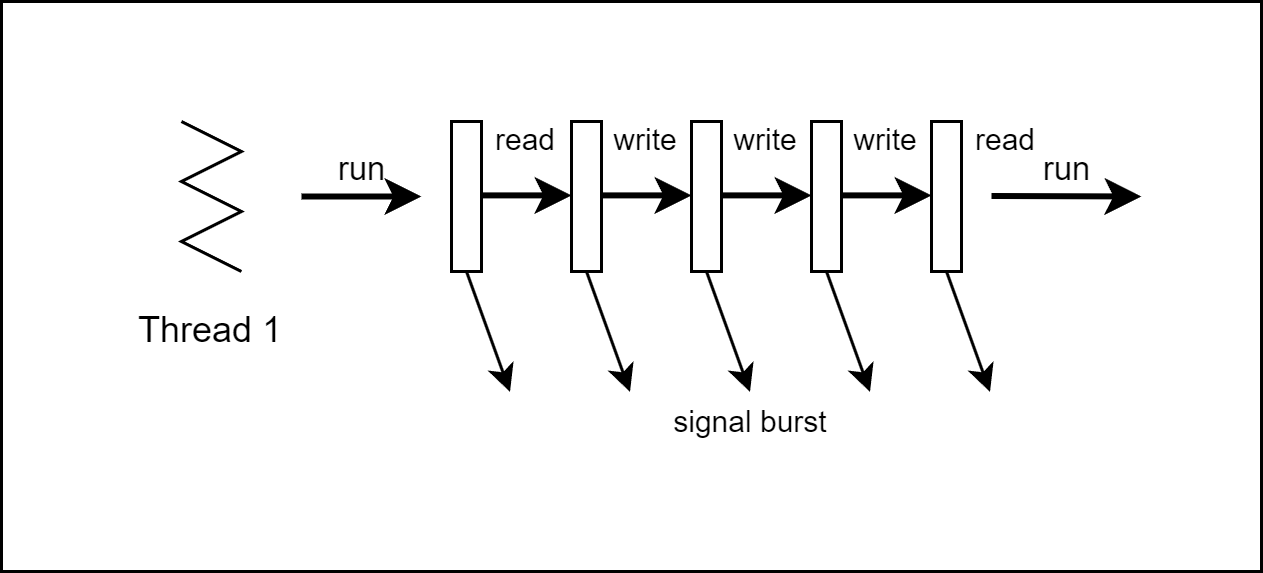 [그림05] 3.2 이전 버전의 신호 burst
[그림05] 3.2 이전 버전의 신호 burst
GIL of Python >= 3.2
새로운 GIL
GIL thrashing을 해결하기 위해 3.2버전부터 동작 방식을 변경합니다.
ticks을 설정하는 대신 GIL의 해제를 담당하는 전역 변수 gil_drop_request를 도입합니다.
thread는 이 변수가 1이 되기 전까지 작업을 수행하고 특정 시점이 되면 반드시 해제됩니다.
동작 방식
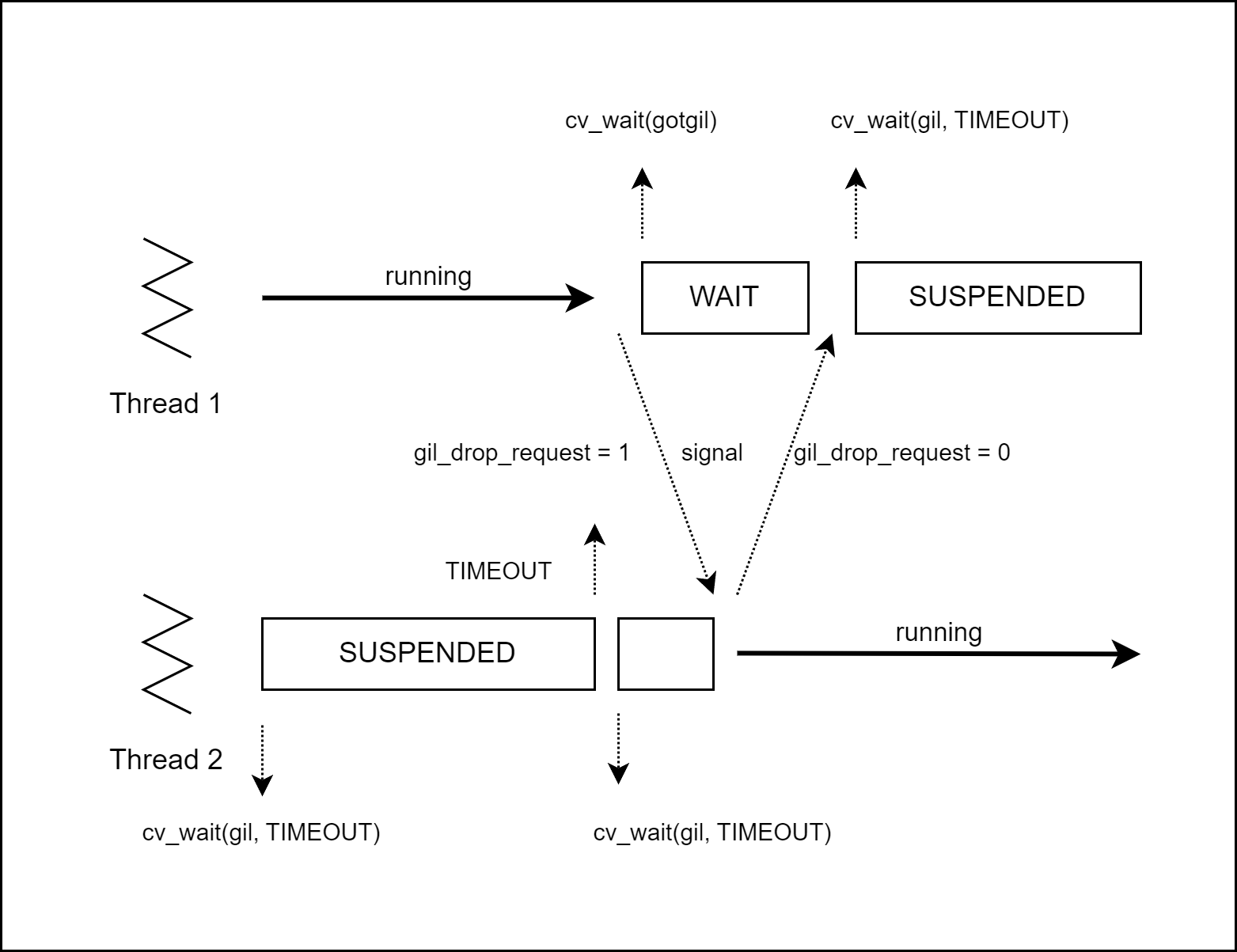 [그림06] 3.2 이상 버전의 GIL
[그림06] 3.2 이상 버전의 GIL
- GIL을 획득한 thread1은 작업을 수행합니다. GIL을 얻지 못한 thread2는 중단 상태입니다.
- thread2에서 GIL을 기다리는 타이머를 설정합니다. 그동안 GIL을 획득한 thread1의 GIL 해제를 기다립니다.
thread1에서 자발적으로 GIL을 해제한다면 thread2가 작업을 수행합니다.
그렇지 않다면 다음 과정이 이어집니다.
- thread2에서
gil_drop_request를 체크하고 다시 GIL을 기다리는 타이머를 설정합니다. - thread1은 이를 확인하고 작업을 중단합니다. 이후 signal을 보내고 ack를 기다리는 타이머를 설정합니다.
- signal을 받은 thread2는 ack를 보내고 작업을 시작합니다.
- ack를 받은 thread1은 GIL을 기다리는 타이머를 설정합니다.
여전히 존재하는 단점
하지만 여전히 몇 가지 단점이 존재합니다.
1. 응답시간 증가
I/O를 처리하기 위해서는 통제권을 얻는 타임 아웃 시퀀스를 반드시 거쳐야 합니다.
또한 I/O나 이벤트의 높은 우선순위는 무시합니다.
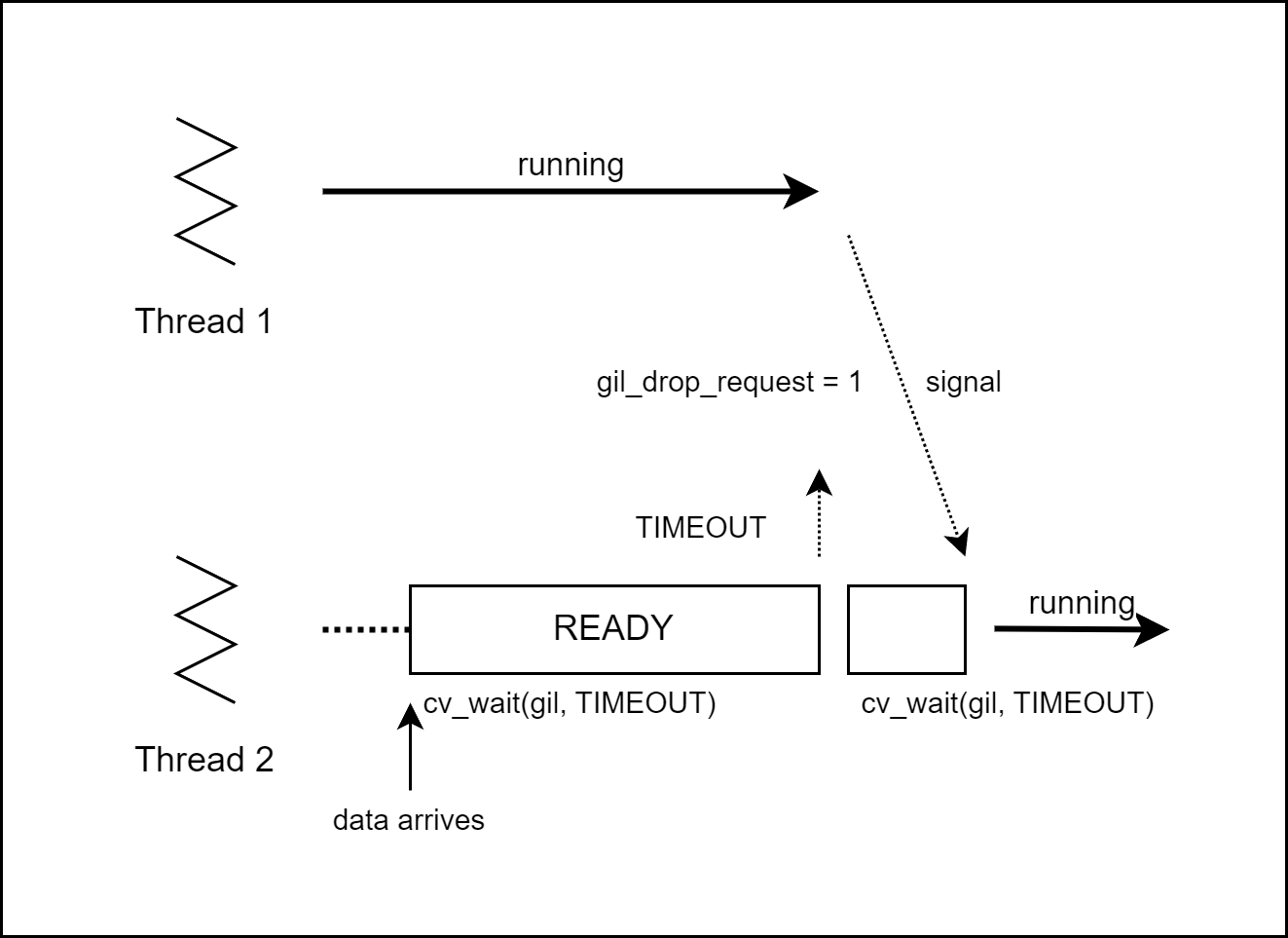 [그림07] 3.2 이상 버전의 응답시간
[그림07] 3.2 이상 버전의 응답시간
2. 불평등한 기상과 기아상태
가장 적절한 스레드가 GIL을 획득하지 못 할 수 있습니다.
이는 내부 상태 변수의 큐가 발생시킵니다.
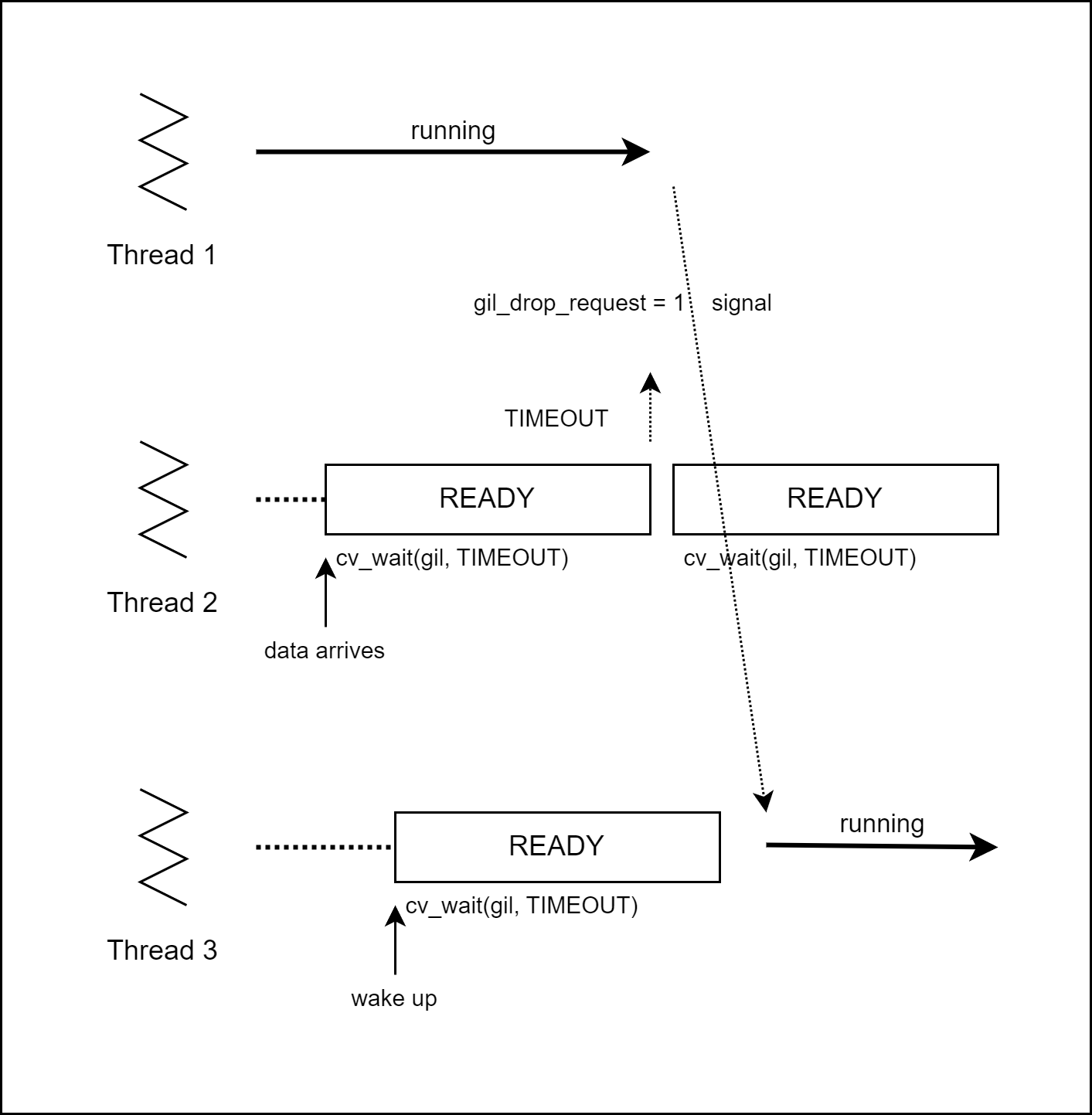 [그림08] 3.2 이상 버전의 기아상태
[그림08] 3.2 이상 버전의 기아상태
3. 호위 효과(Convey Effect)
새로운 GIL에서는 block 되지 않은 I/O 명령이 정체를 일으킵니다.
I/O 명령은 반드시 GIL을 해제하므로 CPU bound 스레드는 항상 재시작을 시도합니다.
I/O가 완료되면 GIL은 해제하고 타임 아웃을 반복합니다.
결과적으로 실행시간이 긴 thread1을 대기하면서 실행시간이 짧은 thread2은 대기하는 호위 효과가 발생합니다.
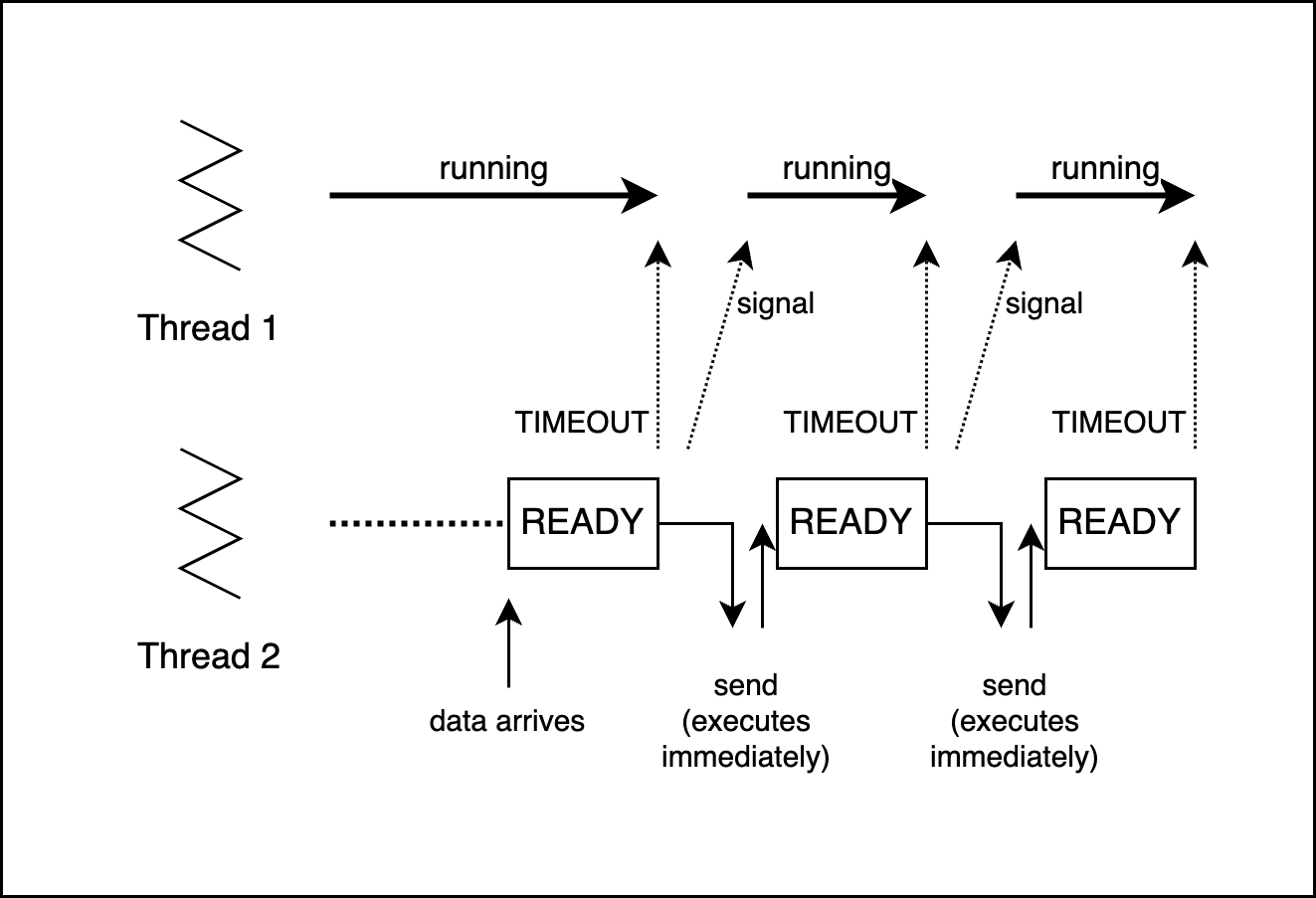 [그림09] 3.2 이상 버전의 호위효과
[그림09] 3.2 이상 버전의 호위효과
GIL의 개선
그렇다면 GIL을 보다 개선할 수 있을까요??
해당 내용은 다양한 분야의 개념이 섞여있는 주제여서 제가 이해하는 데 무리가 있었습니다…
그래서 다양한 사례를 소개하는 것으로 대체하겠습니다.
1. 우선순위와 선점
CPU bound 스레드와 I/O bound 스레드를 분리하는 방법이 있을 것으로 생각됩니다.
또한 높은 우선순위의 스레드는 낮은 우선순위의 스레드로부터 반드시 먼저 선점할 수 있어야 합니다.
2. PEP 554와 PEP 684
GIL을 개선하기 위한 PEP입니다.
PEP 554는 새로운 모듈인 interpreters에 대한 내용을 담고 있으며 PEP 684는 C-API 에서 GIL을 수정한 제안입니다.
조금 더 살펴보면 다음과 같습니다.
| 항목 | pep554 | pep684 |
|---|---|---|
| 목적 | 동일 프로세스에서 다수의 interpreter 활성화 | C-API에서 per-interpreter 제공 |
| 상태 | Draft(선정) | Accepted(채택) |
| 버전 | 3.13 | 3.12 |
| 대상 | Python 사용자 | C-API 개발자 |
따라서 일반적인 사용자라면 3.13에 추가될 기능인 interpreters를 고려해봄직 합니다.
3. GIL 제거
지금까지의 모든 내용은 GIL이라는 작은 lock에서 시작되었습니다.
하지만 GIL을 제거하기 위한 파이썬의 수정은 기하급수적으로 어려운 프로젝트입니다.
GIL을 제거하려는 많은 시도가 있었지만 싱글 thread의 성능이 저하되는 부작용 등으로 인해 도입되지 못했습니다.
또한 GIL을 바탕으로 동작하는 수많은 라이브러리가 존재하며 이는 GIL을 제거하기보다 우회하는 선택으로 내몰린다고 생각합니다.
마무리하며
이번 글에서는 파이썬의 GIL에 대해 알아보았습니다.
GIL은 파이썬 초창기에 Thread Safe을 위해 만들어졌습니다.
동작 방식은 3.2 버전 이전의 ticks 방식과 이상의 signal 방식으로 나뉩니다.
현대의 멀티코어 환경에서는 GIL로 인해 다양한 문제에 직면할 수 있지만 기존 라이브러리와의 호환성 등으로 이를 걷어내기 쉽지 않습니다.
개인적으로 멀티 스레드를 제한하는 GIL이 도대체 무엇인지 확인을 해보고 싶었습니다.
그래서 스레드와 프로세스, 파이썬 interpreter, lock 등 개념부터 PEP에 이르기까지 다양한 자료를 확인했습니다.
부족한 지식으로 최대한 글을 작성해보았습니다만 오류나 잘못된 내용은 언제나처럼 남겨주세요!
끝으로 파이썬을 개발한 귀도 반 로섬이 GIL 관련 문의에 답긴 답변으로 마무리하겠습니다.
이 글이 조금이나마 도움이 되셨으면 합니다.
감사합니다. 😀
… But I also don’t expect it to go away until someone other than me goes through the effort of removing it, and showing that its removal doesn’t slow down single-threaded Python code.
… 하지만 저 이외의 다른 누군가가 이 문제를 제거하고, 이 문제를 제거해도 싱글 스레드 파이썬 코드의 속도가 느려지지 않는다는 것을 증명하기 전까지는 이 문제가 사라질 것이라고 기대하지도 않습니다.
참고 문헌
- Thread State and the Global Interpreter Lock, https://docs.python.org/3/c-api/init.html#thread-state-and-the-global-interpreter-lock
- global interpreter lock, https://docs.python.org/3/glossary.html#term-global-interpreter-lock
- GlobalInterpreterLock, https://wiki.python.org/moin/GlobalInterpreterLock
- POSIX, https://en.wikipedia.org/wiki/POSIX
- pthreads, https://en.wikipedia.org/wiki/Pthreads
- PEP 554 – Multiple Interpreters in the Stdlib, https://peps.python.org/pep-0554/
- PEP 684 – A Per-Interpreter GIL, https://peps.python.org/pep-0684/
- Understanding the Python GIL, https://www.dabeaz.com/GIL/
- It isn’t Easy to Remove the GIL, https://www.artima.com/weblogs/viewpost.jsp?thread=214235
- [번역] 파이썬 GIL은 사라질까? (Has the Python GIL been slain?), https://www.seonghyeon.dev/has-the-python-gil-been-slain/
- What Is the Python Global Interpreter Lock (GIL)?, https://realpython.com/python-gil/