[Develop] 한글 인코딩 UTF-8, CP949, EUC-KR 살펴보기
인코딩의 개념과 한글에 주로 쓰이는 인코딩 UTF-8, CP949, EUC-KR에 대해 살펴봅니다.
개요
안녕하세요.
이번 글은 인코딩의 개념과 한글에 주로 쓰이는 인코딩 UTF-8, CP949, EUC-KR에 대해 살펴보겠습니다.
인코딩에 대해
인코딩과 디코딩
인코딩(Encoding)은 데이터를 코드화하고 압축하는 작업을 의미합니다.
반대로 디코딩(Decoding)은 이러한 코드를 원래의 데이터로 변환하는 작업입니다.
그게 무슨 소리죠??
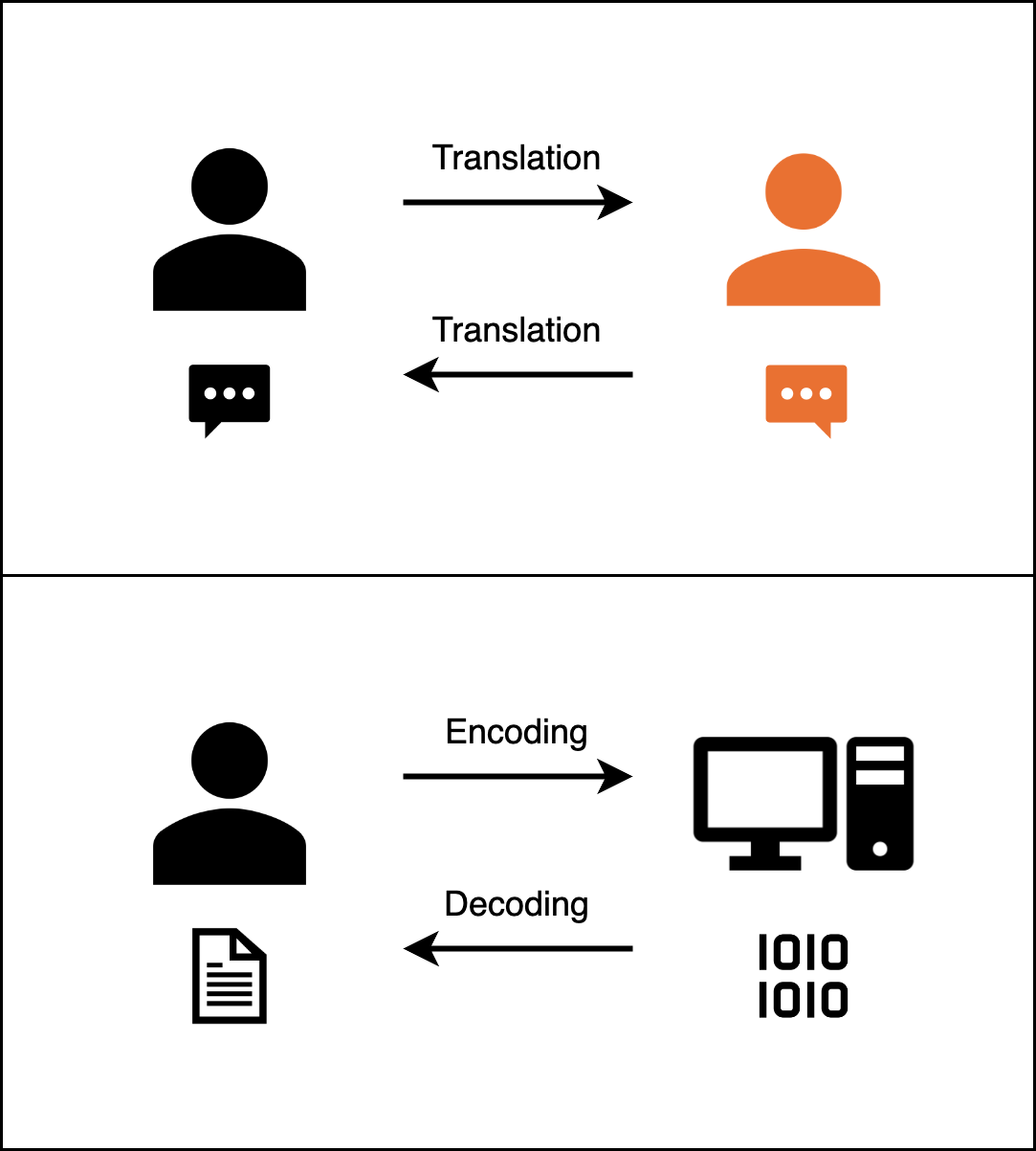 [그림01] 인코딩과 디코딩 예시
[그림01] 인코딩과 디코딩 예시
사람을 한국인, 컴퓨터를 외국인이라고 생각해봅시다.
한국인은 한국말을 할 줄 알고 외국인은 외국어를 할 줄 알겠죠??
한국인이 외국인에게 말할 때 한국어 대신 외국어로 이야기한다고 가정해보겠습니다.
이렇게 한국어(사람이 이해하는 데이터)를 외국어(컴퓨터가 사용하는 0과 1)로 번역하는 것이 인코딩입니다.
반대로 외국인이 대화를 위해 한국어로 번역한다면 이는 디코딩이 됩니다!
인코딩의 종류는??
아주 다양합니다.
우리가 이해하는 문자를 0과 1로 바꾸는 작업도 있구요.
음파와 같은 아날로그 데이터를 디지털로 바꾸는 작업도 인코딩입니다.
여기서는 전자인 문자의 인코딩를 다뤄보겠습니다.
한글 인코딩
1. EUC-KR
EUC-KR은 한국 산업 표준 인코딩으로 완성형 인코딩입니다.
완성형은 한글 1개의 문자를 온전히 변환하는 방식입니다.
이와 반대인 조합형의 경우 자음과 모음으로 분리하여 저장하는 방식입니다.
EUC-KR은 모든 완성형 문자가 아니라 빈도수를 기준으로 2,350자만 변환하는데요.
이는 2bytes로 인코딩을 진행하는 당시의 국제표준을 살펴봐야 합니다.
1byte를 온전히 다 사용한다면 128개를 표현할 수 있으므로 2bytes는 128 ^ 2 = 16,384개를 표현할 수 있습니다.
하지만 가장 앞 비트는 제어문자와 관련되어 문제를 일으킬 수 있었고 실제로 표현할 수 있는 수는 94개 또는 96개였습니다.
96 ^ 2 = 9,216개이므로 모든 완성형 문자의 개수인 11,172개를 표현할 수 없었고 그로 인해 EUC-KR은 반쪽짜리 완성형이 됩니다.
2. CP949
CP949는 Microsoft의 한국어 기본 코드 페이지로 직전의 설명드린 EUC-KR의 확장형입니다.
EUC-KR에서 담기지 못한 나머지 완성형 글자를 모두 변환합니다.
또한 확장형답게 EUC-KR 인코딩 파일을 지원합니다.
3. UTF-8
UTF-8은 유니코드 중 하나로 문자를 1~4바이트에 저장하는 가변형 인코딩입니다.
1바이트는 아스키 코드와의 하위호환이며 한글은 주로 3바이트에 분포합니다.
UTF-16이나 UTF-32와 다르게 1가지 형식만 존재하므로 다양한 확장 기능 혹은 다른 타입에 대해 고려하지 않아도 됩니다.
덕분에 가장 많이 사용되며 여러 프로그램에서 기본값인 경우를 흔히 볼 수 있습니다.
하지만 한글에서는 1. 정규화와 2. 정준분해 또는 호환분해로 인해 조금 복잡해는데요.
구체적으로는 아래 표와 같이 4가지로 나뉩니다.
| 조합형 | 완성형 | |
|---|---|---|
| 정준분해 | NFD | NFC |
| 호환분해 | NFKD | NFKC |
먼저 정규화는 한글을 조합형(NFD, NFKD)으로 저장할지 완성형(NFC, NFKC)으로 저장할지의 구분입니다.
예를 들어 각이라는 문자는 조합형과 완성형에 따라 다음과 같이 저장합니다.
- 조합형:
ㄱㅏㄱ(1100 + 1161 + 11A8) - 완성형:
각(AC01)
두번째인 정준분해(NFD, NFC) 또는 호환분해(NFKD, NFKC)는 특수문자를 치환할지의 구분입니다.
예를 들어 ㈀라는 특수문자의 경우 분해에 따라 다음과 같이 저장합니다.
- 정준분해:
㈀(3200) - 호환분해:
(ㄱ)(0028 + 1161 + 0029)
사례
윈도우 PC를 따로 준비하지 않아 아래의 내용은 모두 맥에서 진행했습니다..!
같은 한글인데 인코딩이 서로 달라요!
우선 file 명령어를 이용해 인코딩을 확인합니다.
1
2
3
4
5
6
7
# Mac
$ file -bI test.csv
text/csv; charset=utf-8
# Linux
$ file -bi test.csv
text/csv; charset=utf-8
만약 원하는 인코딩이 아니라면 변경해야겠죠??
인코딩 변경은 iconv 명령어로 가능합니다.
1
$ iconv -c -f [원본인코딩] -t [변경후인코딩] [원본파일명] > [변경후파일명]
같은 유니코드인데 서로 다르다고 해요!
저는 다음의 파이썬코드를 통해 문자열을 변환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
import unicodedata
import sys
import pathlib
import argparse
def parse_command_argv():
parser = argparse.ArgumentParser(description="Text normalization tool")
group_text_file = parser.add_mutually_exclusive_group(required=True)
parser.add_argument("normalize_type", help="Type of normalization to perform", choices=["NFC", "NFD", "NFKC", "NFKD"])
group_text_file.add_argument("-t", "--text", help="Text to convert")
group_text_file.add_argument("-f", "--file", nargs=2, metavar=("ORIGIN_FILE", "CONVERTED_FILE"), help="File to convert")
return parser.parse_args()
def read_text_from_file(file_path):
try:
with open(file_path, encoding='utf-8') as file:
return file.read()
except FileNotFoundError:
raise Exception("01", f"File not found: {file_path}")
except UnicodeDecodeError:
raise Exception("02", f"Cannot decode file: {file_path}")
def write_text_to_file(text, file_path):
try:
with open(file_path, "x", encoding='utf-8') as file:
file.write(text)
except FileExistsError:
raise Exception("03", f"File already exists: {file_path}")
except OSError:
raise Exception("04", f"Cannot write to file: {file_path}")
if __name__ == "__main__":
args = parse_command_argv()
normalize_type = getattr(args, "normalize_type")
try:
if getattr(args, "text"):
converted_text = unicodedata.normalize(normalize_type, getattr(args, "text"))
print(converted_text)
else:
origin_file_path, converted_file_path = getattr(args, "file")
origin_file_path = pathlib.Path(origin_file_path)
origin_text = read_text_from_file(origin_file_path)
if not origin_text:
raise Exception("05", "File is empty")
converted_text = unicodedata.normalize(normalize_type, origin_text)
write_text_to_file(converted_text, converted_file_path)
except Exception as e:
error_code, error_message = e.args
print(error_message)
sys.exit(int(error_code))
다음은 간단한 사용 예시입니다.
1
2
3
4
5
6
7
# 1. -t
$ python normalize_convertor.py -t 안녕하세요 NFC
안녕하세요
# 2. -f
$ echo "안녕하세요" > sample.txt
$ python normalize_convertor.py -f sample.txt converted.txt NFC
마무리하며
이번 글에서는 인코딩에 대해 살펴봤습니다.
협업하는 분들의 OS가 Mac과 윈도우 모두 섞여 있어 인코딩 관련 문제가 종종 발생합니다.
인코딩과 관련해서는 다양한 해결책이 있으니 각자 상황에 맞게 해결되기를 바랍니다~!
이 글이 조금이나마 도움이 되셨으면 합니다.
감사합니다. 😀
참고 문헌
- Extended Unix Code, https://en.wikipedia.org/wiki/Extended_Unix_Code#EUC-KR
- CP949, https://en.wikipedia.org/wiki/Unified_Hangul_Code
- Unicode, https://en.wikipedia.org/wiki/Unicode
- 한글과 유니코드, Pusnow, https://gist.github.com/Pusnow/aa865fa21f9557fa58d691a8b79f8a6d