[Data] [빅데이터를 지탱하는 기술] 정리하기 - 1-1 [배경] 빅데이터의 정착
빅데이터를 지탱하는 기술 시리즈로 1장 1절, 빅데이터의 정착을 정리했습니다.
개요
- [빅데이터를 지탱하는 기술] 정리하기 시리즈
- 1장 빅데이터의 기초 지식
- 2장 빅데이터의 탐색
- 3장 빅데이터의 분산 처리
안녕하세요.
이번 글에서는 “빅데이터를 지탱하는 기술” 이라는 책의 1장 1절, “[배경] 빅데이터의 정착”을 정리했습니다.
분산 시스템에 의한 데이터 처리의 고속화 - 빅데이터의 취급하기 어려운 점을 극복한 2가지 대표 기술
빅데이터의 시작
이 책에서는 빅데이터라는 단어의 대중화를 2011년 후반 ~ 2012년로 봅니다.
당시 기업들은 데이터 처리에 분산 시스템 도입하면서 비지니스에 활용하는 움직임이 일었다고 설명합니다.
하지만 빅데이터의 취급은 여전히 어려운데 대표적으로 다음 2가지 이유가 꼽힙니다.
- 데이터 분석의 방법을 알지 못 함
- 데이터 처리에 인력과 시간이 필요함
이 책은 데이터 처리와 관련된 기술 서적이므로 두 번째 이유에 집중합니다.
빅데이터 기술의 요구 - Hadoop과 NoSQL의 대두
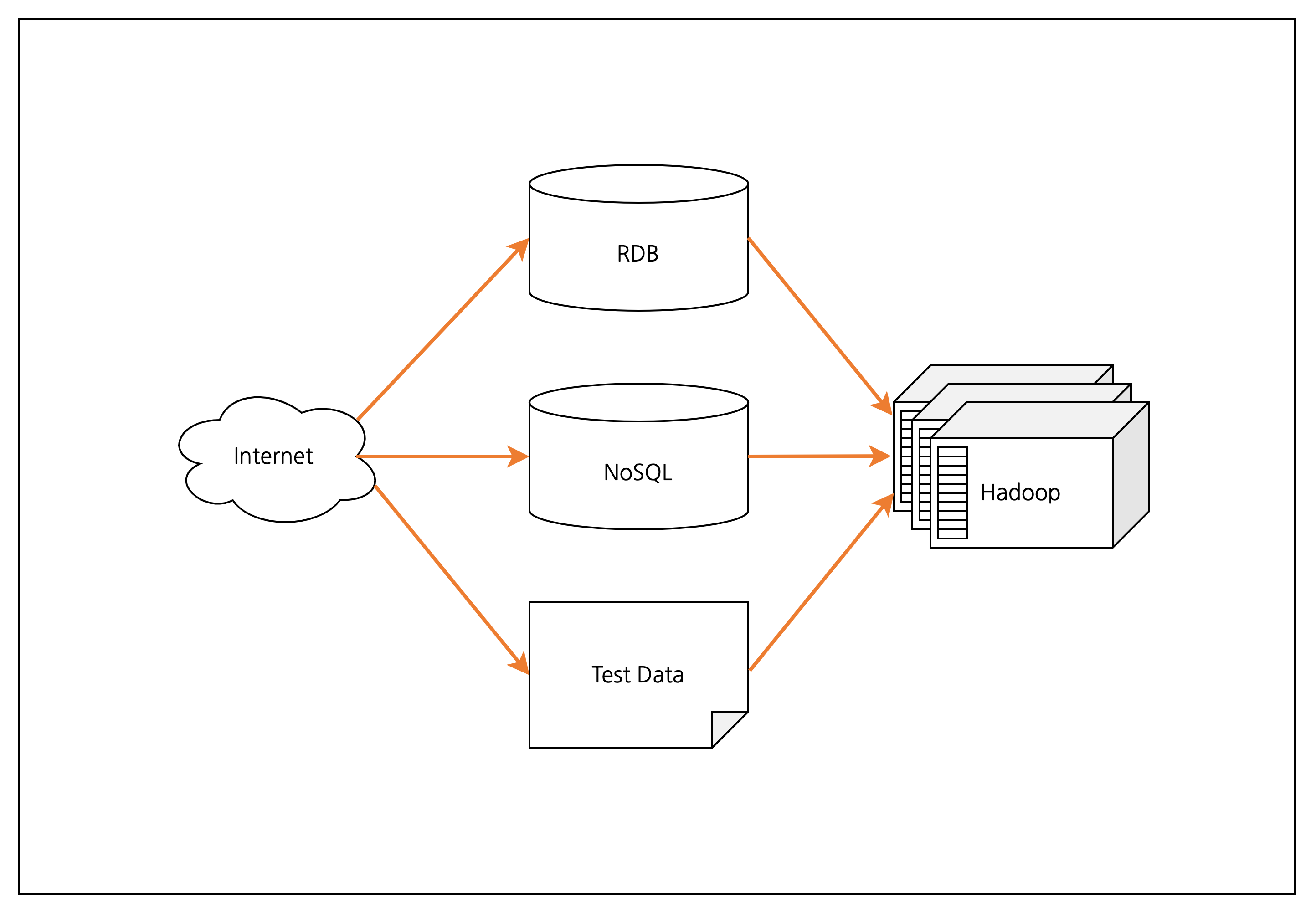 [그림 1] Hadoop과 NoSQL의 위치 관계
[그림 1] Hadoop과 NoSQL의 위치 관계
대표적인 빅데이터 기술에는 Hadoop과 NoSQL이 있습니다.
다양한 시스템에서의 데이터는 이전의 관계형 데이터베이스로 취급하기 불가능했고 이를 해결하고자 Hadoop과 NoSQL이 등장합니다.
Hadoop - 다수의 컴퓨터에서 대량의 데이터 처리
Hadoop은 다수의 컴퓨터에서 대량의 데이터를 처리하기 위한 기술입니다.
Hadoop은 스토리지와 데이터를 순차적으로 처리하는 수백 ~ 수천 대의 컴퓨터를 관리하는 프레임워크입니다.
구글에서 개발된 분산 처리 프레임워크 ‘MapReduce’를 참고하여 제작되었습니다.
그래서 데이터 처리를 위해 Java 언어의 프로그래밍이 필요했습니다.
이를 해결하고자 Hadoop에서의 쿼리 언어 소프트웨어인 Hive를 개발됩니다.
Hive를 통해 Hadoop 접근성이 개선되었고 이후 사용자 확보에 성공적이었다고 합니다.
다음은 2011년까지의 Hadoop의 주요 역사표입니다.
| 시기 | 이벤트 |
|---|---|
| 2004.12. | 구글에서 MapReduce 논문 발표 |
| 2007.09. | Hadoop의 최초 버전(0.14.1)이 베포되어 전 세계적으로 이용 |
| 2009.05. | Hive의 최초 버전(0.3.0) 배포 |
| 2011.12. | Hadoop 1.0.0 배포 |
NoSQL 데이터베이스 - 빈번한 읽기/쓰기 및 분산 처리 강점
NoSQL은 전통적인 RDB 제약 제거를 목표로 한 데이터베이스입니다.
크게 다음과 같은 종류가 존재합니다.
- Key-Value Store(KVS): 다수의 키와 값을 관련지어 저장
- Document Store: JSON과 같은 복잡한 데이터 구조 저장
- Wide-column: 여러키를 사용하여 높은 확장성 제공
각자 추구하는 목표는 다르지만 공통적으로 RDB에 비해 고속의 읽기와 쓰기가 가능하고 분산 처리에 적합하다는 특징을 가집니다.
참고로 Hadoop이 데이터를 나중에 집계하는 것이 목적이라면 NoSQL은 애플리케이션에서 온라인으로 접속하는 데이터베이스입니다.
다음은 2011년까지의 NoSQL의 주요 역사표입니다.
| 시기 | 이벤트 | 종류 |
|---|---|---|
| 2009.08. | MongoDB 1.0 배포 | Document |
| 2010.07. | CouchDB 1.0 배포 | Document |
| 2011.09. | RIak 1.0 배포 | Key-Value |
| 2011.10. | Cassandra 1.0 배포 | Wide-column |
| 2011.12. | Redis 1.0 배포 | Key-Value |
NoSQL 데이터베이스 - Hadoop과 NoSQL 데이터베이스의 조합 - 현실적인 비용으로 대규모 데이터 처리 실현
이 두 가지 기술은 "NoSQL 데이터베이스에 기록 및 Hadoop으로 분산 처리"라는 조합으로 널리 퍼집니다.
기존의 기술로 불가능 또는 고가의 하드웨어가 필요했지만 위 조합을 통해 현실적인 비용으로 데이터를 처리할 수 있게 됩니다.
분산 시스템의 비즈니스 이용 개척 - 데이터 웨어하우스와의 공존
한편, 이전부터 일부 기업에서는 엔터프라이즈 데이터 웨어하우스(Enterprise data warehouse/EDW, 또는 데이터 웨어하우스/DWH)를 도입했습니다.
이를 분석해 업무 개선과 경영 판단의 자료로 활용했습니다.
이후 분산 시스템 발전하면서 기존의 데이터 웨어하우스 제품이 사용되는 경우에도 Hadoop 사용하는 경우가 증가합니다.
대량의 데이터를 보존 및 집계하기 위해 Hadoop과 Hive를 사용하면서 Hadoop 도입을 기술적으로 지원하는 비즈니스가 성립됩니다.
이 과정에서 드디어 “빅데이터”라는 키워드가 등장합니다.
전통적 데이터 웨어하우스 역시 대량의 데이터 처리와 Hadoop 대비 우수한 장점이 있습니다.
하지만 일부 제품의 경우 안정적 성능을 위해 H/W + S/W 통합 장비(appliance)로 제공 등의 단점이 존재합니다.
이는 데이터 용량 확장에 어려움을 가져왔고 가속도적으로 늘어나는 데이터는 Hadoop, 작거나 중요한 데이터 데이터 웨어하우스로 구분하게 됩니다.
예를 들어 야간 배치에서 대량으로 발생하는 데이터의 처리는 Hadoop을 이용하고 그 결과를 데이터 웨어하우스에 저장해 부하를 감소시킵니다.
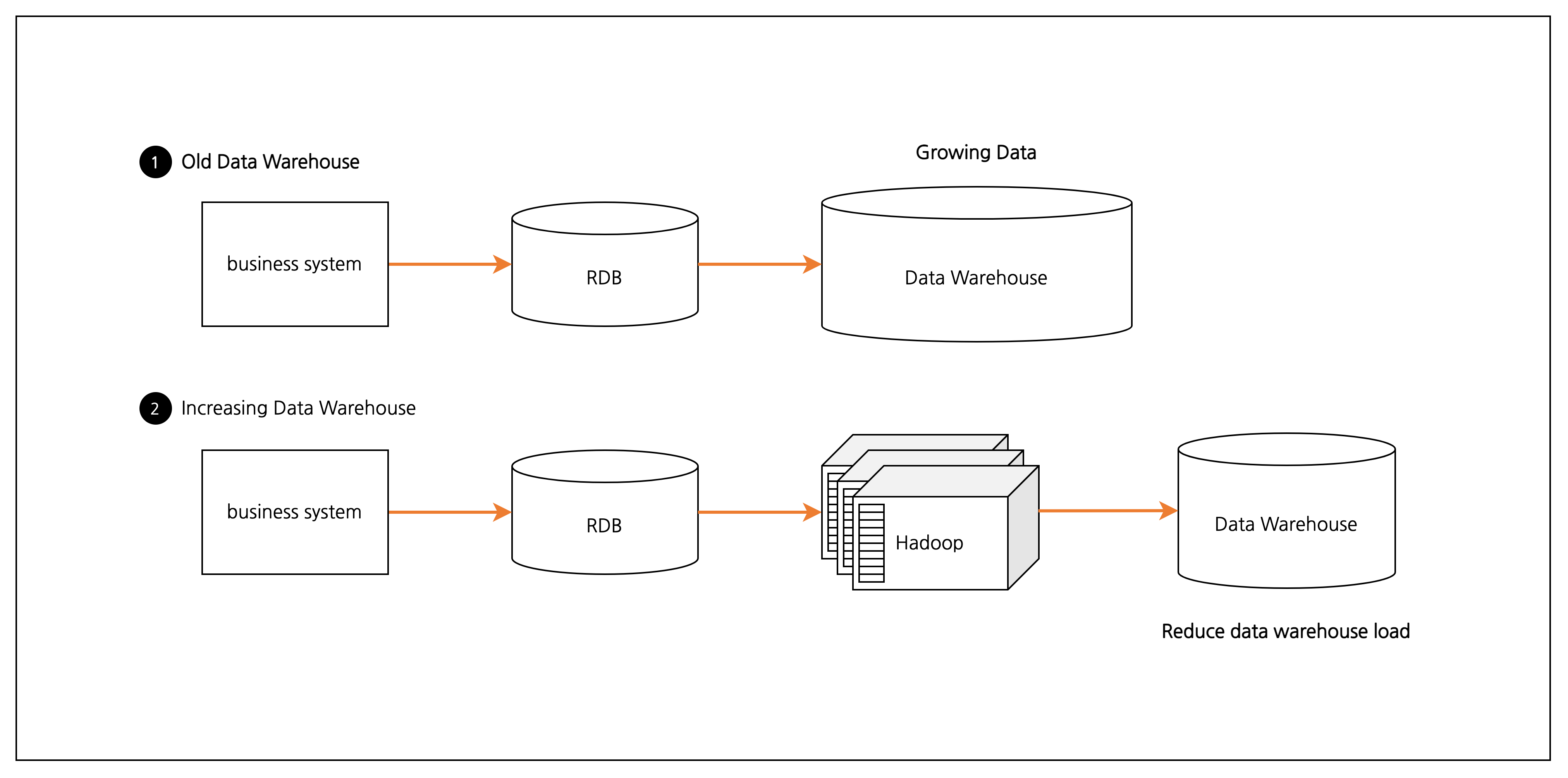 [그림 2] Hadoop에 의한 데이터 웨어하우스의 증가
[그림 2] Hadoop에 의한 데이터 웨어하우스의 증가
직접 할 수 있는 데이터 분석 폭 확대 - 클라우드 서비스와 데이터 디스커버리로 가속하는 빅데이터의 활용
클라우드 서비스 보급
이와 비슷한 시기에 클라우드 서비스가 보곱되면서 빅데이터의 활용이 증가합니다.
분산처리를 위한 하드웨어의 준비와 관리를 클라우드 서비스를 통해 해결한 것이죠!
다음은 데이터 처리를 위한 클라우드 서비스 중 일부입니다.
| 시기 | 이벤트 | 서비스 특징 |
|---|---|---|
| 2009.04. | Amazon Elastic MapReduce | 클라우드를 위한 Hadoop |
| 2010.05. | 구글 BigQuery 발표 | 데이터 웨어하우스 |
| 2012.10. | Azure HDInsight | 클라우드를 위한 Hadoop |
| 2012.11. | Amazon Redshift | 데이터 웨어하우스 |
데이터 디스커버리의 기초지식 - 셀프서비스용 BI 도구
빅데이터 기술이 나오기 시작한 시기에 데이터 웨어하우스의 데이터를 시각화하는 방법으로 데이터 디스커버리(Data Discovery)가 인기를 끌게 됩니다.
데이터 디스커버리는 “대화형으로 데이터를 시각화하여 가치 있는 정보를 찾으려고 하는 프로세스”를 의미합니다.
또한 데이터 디스커버리는 “셀프서비스용 BI 도구”라고도 불립니다.
BI 도구(Business Intelligence Tool)은 데이터 웨어하우스와 조합되어 사용된 경영자용 시각화 서비스입니다.
셀프서비스용 BI 도구는 이를 개인도 도입할 수 있을 정도로 단순화한 것으로 이로 인해 많은 사람이 데이터를 살펴볼 수 있게 되었습니다.
2013년 이후 Apache Spark와 같은 새로운 분산 시스템용 프레임워크가 보급되어 배치 처리뿐만 아니라 실시간 데이터 처리 시스템도 만들어집니다.
마무리하며
이번 글에서는 빅데이터의 역사에 대해 간략하게 알아보았습니다.
기존의 전통적인 데이터 웨어하우스와 단일 데이터 처리에서 NoSQL과 Hadoop로 대표되는 저장 및 분산처리 기술의 등장을 통해 대용량의 데이터를 처리하게 됩니다.
이 글이 조금이나마 도움이 되셨으면 합니다.
감사합니다. 😀
참고 문헌
- 니시다 케이스케, 빅데이터를 지탱하는 기술, 제이펍, 2018